BDD(Berkeley DeepDrive Dataset) Use Case
데이터셋 소개

BDD100K는 100,000개의 주행 동영상으로 구성된 Computer Vision 데이터셋이다. 각 동영상은 40초 길이, 720p 해상도, 30fps로 제공되며, 수직 차선은 빨간색, 평행 차선은 파란색으로 표시된다. 데이터셋은 객체 인식 및 추적에 유용한 2D Bounding Box 주석이 포함되어 있으며, 각 프레임마다 운전 가능 지역, 차선 표시 등의 정보가 제공된다. BDD100K는 자율 주행 차량, 교통 안전 및 보안, 인간 행동 및 인지 모델링 등 다양한 분야에서 활용될 수 있다.
train 개수 : 70000, val 개수 : 10000
instance 개수
1: pedestrian: 129262
2: rider: 6461
3: car: 1021857
4: truck: 42963
5: bus : 16505
6: train: 179
7: motorcycle: 4296
8: bicycle : 10229
9: traffic light : 265906
10: traffic sign : 343777
실험 소개
본 실험은 전체 데이터셋 중 training set (약 70%), validation set (10%)이 주어진 상태에서 training set 중 랜덤으로 선별한 10%를 레이블링하여 학습 시킨 상황을 가정하여 시작합니다.
- 사용된 모델은
yolov5s이며,현재 10% 학습시킨 상황에서 모델의 정확도 (mAP@50)는35.3%입니다. - 본 실험의 목표는 가정된 상항에서 10%의 추가 학습 데이터를 선별하여 모델의 성능을 높이는 것입니다.
셀렉트스타의 큐레이션 기법을 사용하여 랜덤 30%와 큐레이션 30%간의 성능을 비교합니다.
큐레이션이란?
- 테스트 데이터를 기준으로 사용자가 원하는 큐레이션 개수 만큼 k-means 군집을 형성한다.
- 형성된 테스트 데이터의 기준점을 기준으로 labeling 되지 않은 데이터 중 가장 가까운 데이터를 선택한다.
- 선택된 데이터 추출 및 추천
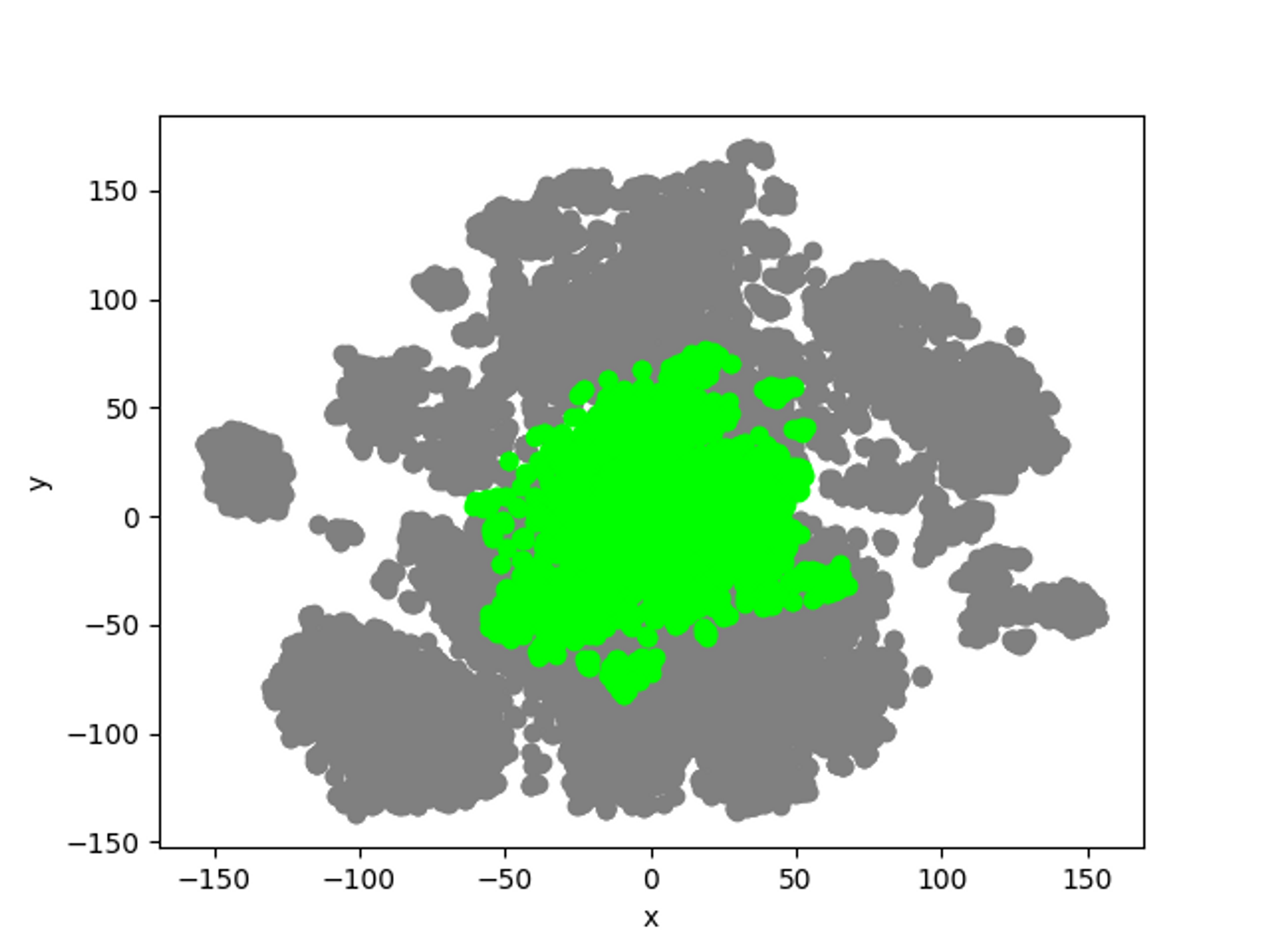
큐레이션 사용 전
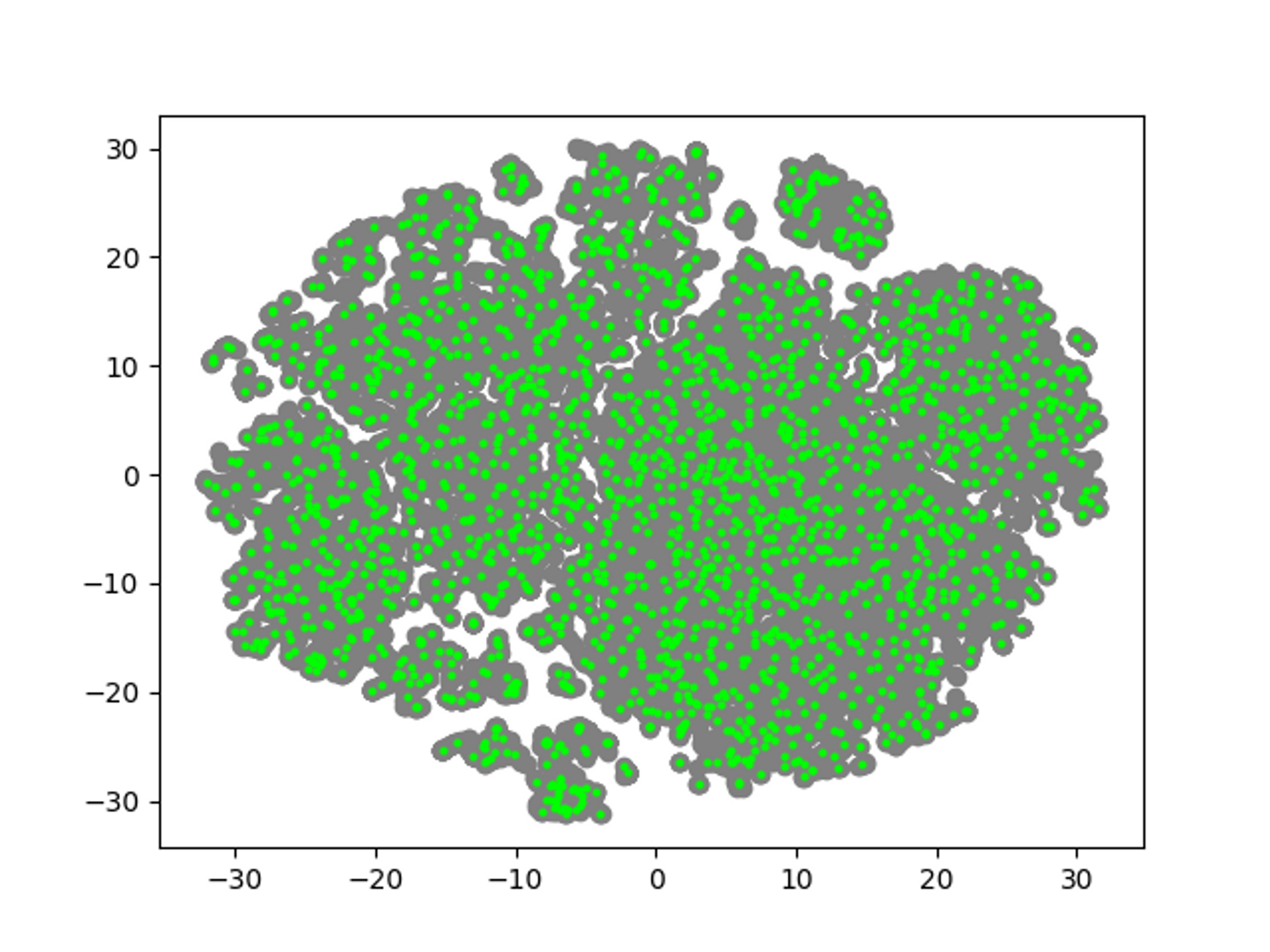
큐레이션 사용 후
결과
 K-means 20% 큐레이션 정확도(mAP@50) : 40.0
K-means 20% 큐레이션 정확도(mAP@50) : 40.0
 Random 20% 정확도(mAP@50) : 38.2
Random 20% 정확도(mAP@50) : 38.2
Appendix - model zoo
| model | 학습 퍼센트 | mAP@50 |
|---|---|---|
yolov5s | 랜덤 10% | 35.3 |
yolov5s | 큐레이션 10% | 36.6 |
yolov5s | 랜덤 20% | 38.2 |
yolov5s | 큐레이션 20% | 40.0 |
yolov5s | 랜덤 30% | 41.8 |
yolov5s | 큐레이션 30% | 42.0 |
yolov5l | 랜덤 30% | 44.8 |
yolov5l | 큐레이션 30% | 45.9 |