BDD(Berkeley DeepDrive Dataset) Use Case
Introduction to the Dataset

BDD100K is a computer vision dataset consisting of 100,000 driving videos. Each video is 40 seconds long and provided at 720p resolution and 30fps. Vertical lanes are marked in red, and parallel lanes are marked in blue. The dataset includes 2D bounding box annotations useful for object detection and tracking, as well as information such as drivable areas and lane markings for each frame. BDD100K can be used in various fields such as autonomous driving, traffic safety and security, and human behavior and cognition modeling.
Number of training samples: 70,000, number of validation samples: 10,000
Instance counts:
1: pedestrian: 129262
2: rider: 6461
3: car: 1021857
4: truck: 42963
5: bus : 16505
6: train: 179
7: motorcycle: 4296
8: bicycle : 10229
9: traffic light : 265906
10: traffic sign : 343777
Experiment Introduction
This experiment starts from the situation where a training set (approximately 70%) and a validation set (10%) are given from the entire dataset, and 10% of the training set selected randomly is labeled and trained.
- The model used is
yolov5s, and the current accuracy (mAP@50) of the model trained with 10% of the data is35.3%. - The goal of this experiment is to improve the model's performance by selecting 10% of additional training data under the given conditions.
The performance between random 30% and curation 30% is compared using Selectstar's curation technique.
What is Curation?
- The user forms k-means clusters as many as the number of curations desired based on the test data.
- Among the unlabeled data, the data closest to the reference point of the formed test data cluster is selected.
- Extraction and recommendation of selected data.
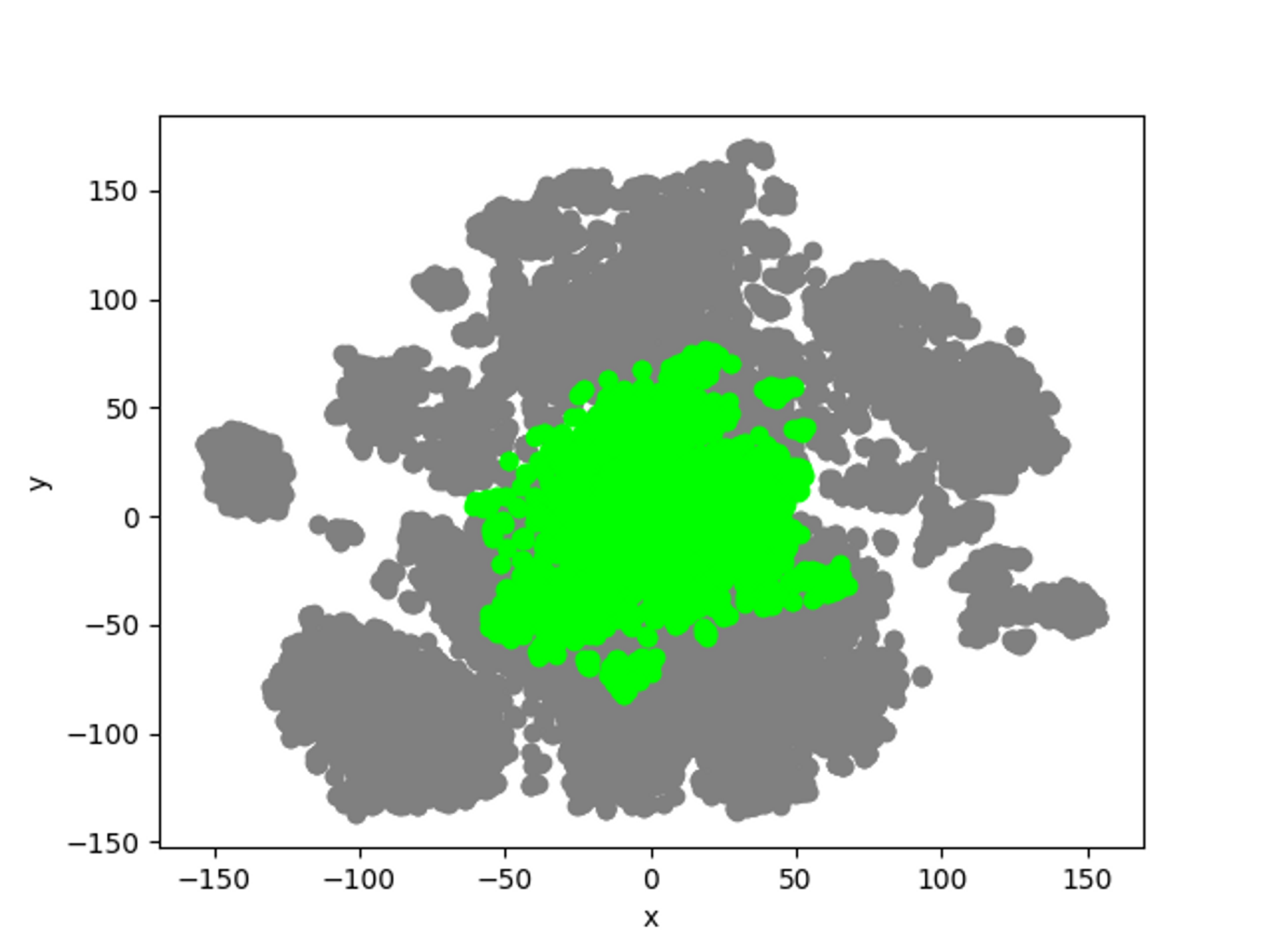
Before using curation
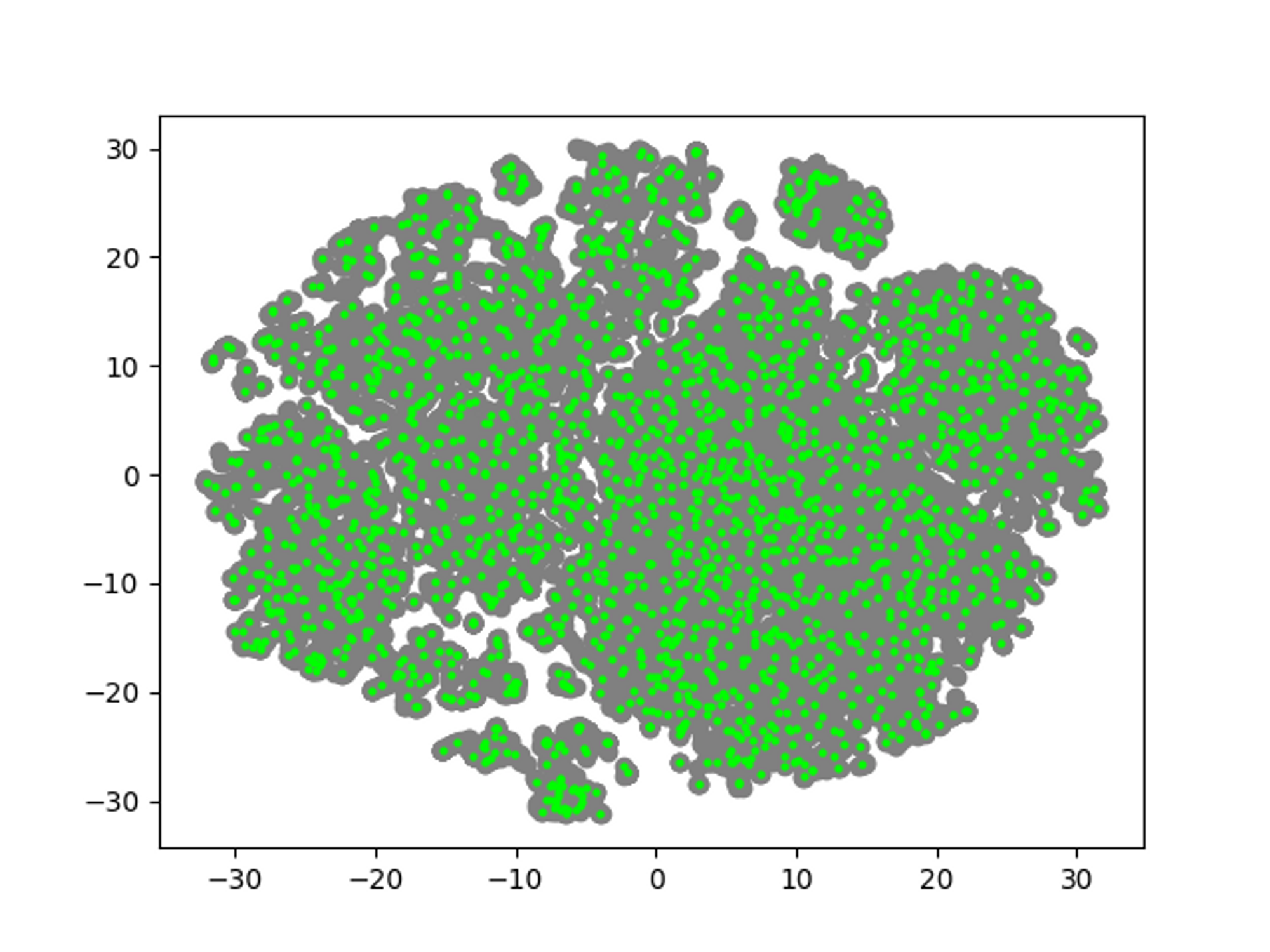
After using curation
Results
 K-means 20% curation accuracy(mAP@50): 40.0
K-means 20% curation accuracy(mAP@50): 40.0
 Random 20% accuracy(mAP@50): 38.2
Random 20% accuracy(mAP@50): 38.2
Appendix - model zoo
| model | Training Percentage | mAP@50 |
|---|---|---|
yolov5s | Random 10% | 35.3 |
yolov5s | Curated 10% | 36.6 |
yolov5s | Random 20% | 38.2 |
yolov5s | Curated 20% | 40.0 |
yolov5s | Random 30% | 41.8 |
yolov5s | Curated 30% | 42.0 |
yolov5l | Random 30% | 44.8 |
yolov5l | Curated 30% | 45.9 |