AID(Aerial Image Dataset) Usage Case
Introduction to the Dataset
AID is a large aerial image dataset generated by collecting sample images from Google Earth images. The dataset consists of 10,000 images and is classified into the following 30 classes:
airport, bare land, baseball field, beach, bridge, center, church, commercial, dense residential, desert, farmland, forest, industrial, meadow, medium residential, mountain, park, parking, playground, pond, port, railway station, resort, river, school, sparse residential, square, stadium, storage tanks, and viaduct.
Dataset Introduction Link
Experiment Introduction
In this experiment, we assume that 30% of the randomly selected dataset is labeled and fixed as a validation set, and the remaining 70% of the data is also randomly selected, and 20% of it is labeled for training.
The efficient model was used as the model,
and the current accuracy of the model trained with 20% of the data is 90.1%.
The goal of this experiment is to select 10% of additional training data under the assumed conditions to improve the performance of the model.
결과
요약
| Use of DATUMO FST | Method of Selecting Additional Training Data | Percentage of Additional Training Data | Accuracy |
|---|---|---|---|
| X | Before Additional Training | 0% | 90.1% |
| X | Random Selection | 10% | 91.3% |
| X | Random Selection | 15% | 92.3% |
| O | Curation of Data Clustered in Distribution | 10% | 92.6% |
| O | Selection of Classes Dispersed in Distribution | 10% | 92.7% |
| X | Random Selection | 20% | 93.0% |
reference, it was found that the performance improvement using DATUMO FST was twice as high as random selection. It was also found that to achieve a similar level of performance when training randomly, about 1.7 times more labeled data was needed.
Curation of Data Clustered in Distribution
Accuracy : 92.6%
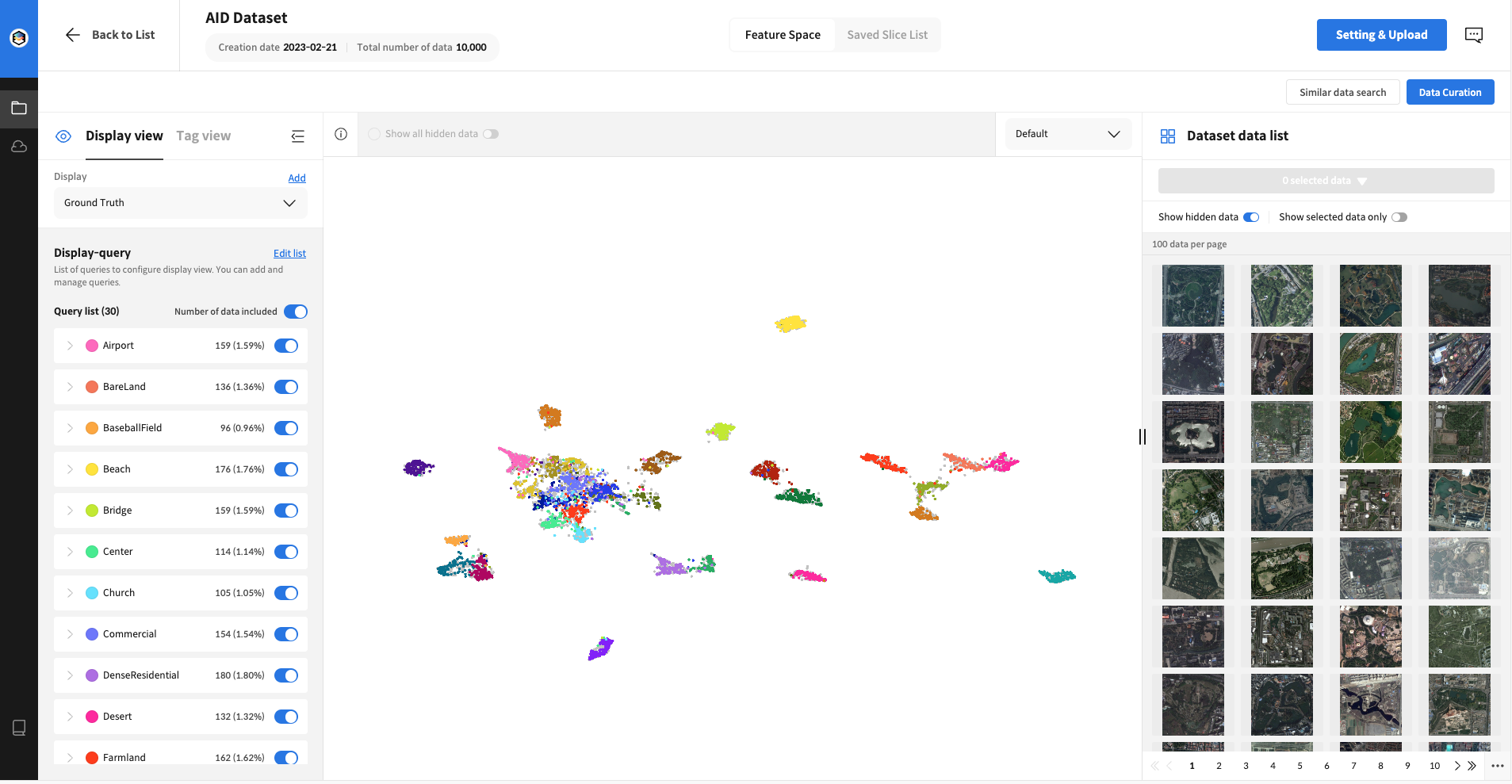 After uploading the image to DATUMO FST, the distribution of the pre-labeled train+validation set was examined, revealing independent areas for each class and areas where multiple classes were clustered together.
After uploading the image to DATUMO FST, the distribution of the pre-labeled train+validation set was examined, revealing independent areas for each class and areas where multiple classes were clustered together.
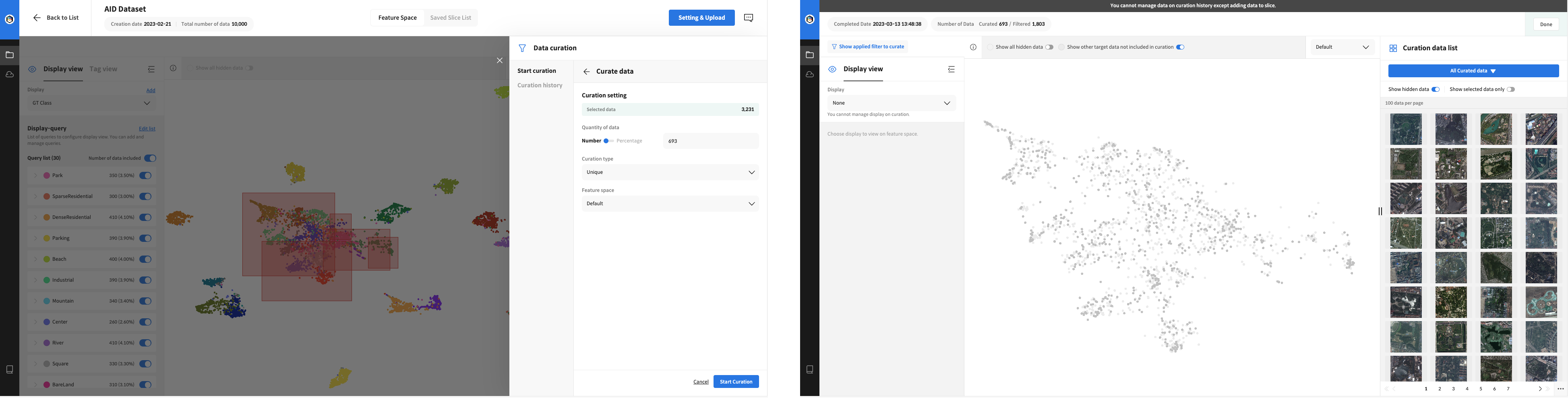 Selected the clustered area and requested curation to proceed with additional learning using 10% of the selected data.
Selected the clustered area and requested curation to proceed with additional learning using 10% of the selected data.
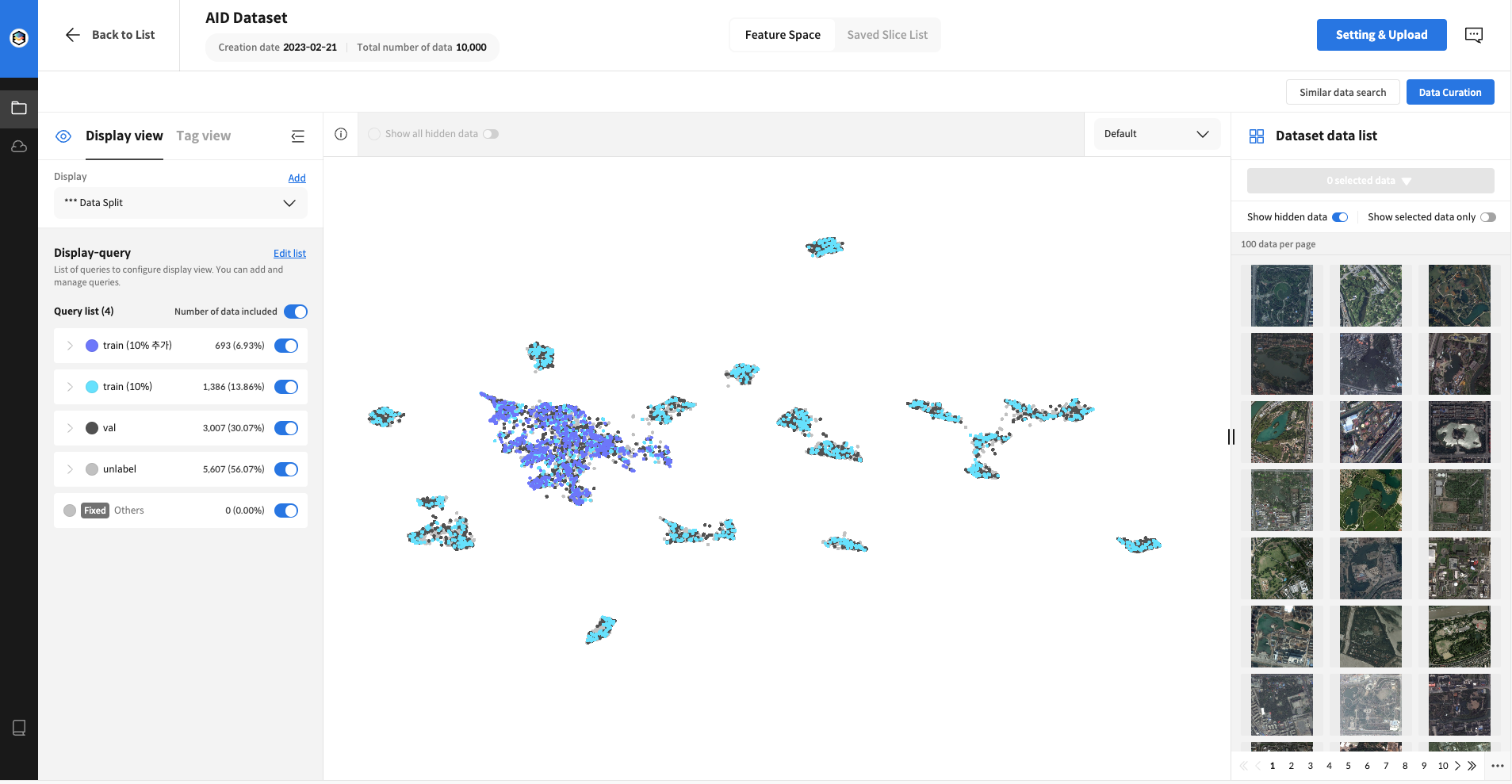 Final Data Split Image
Final Data Split Image
Selection of Variably Distributed Classes
Accuracy: 92.7%
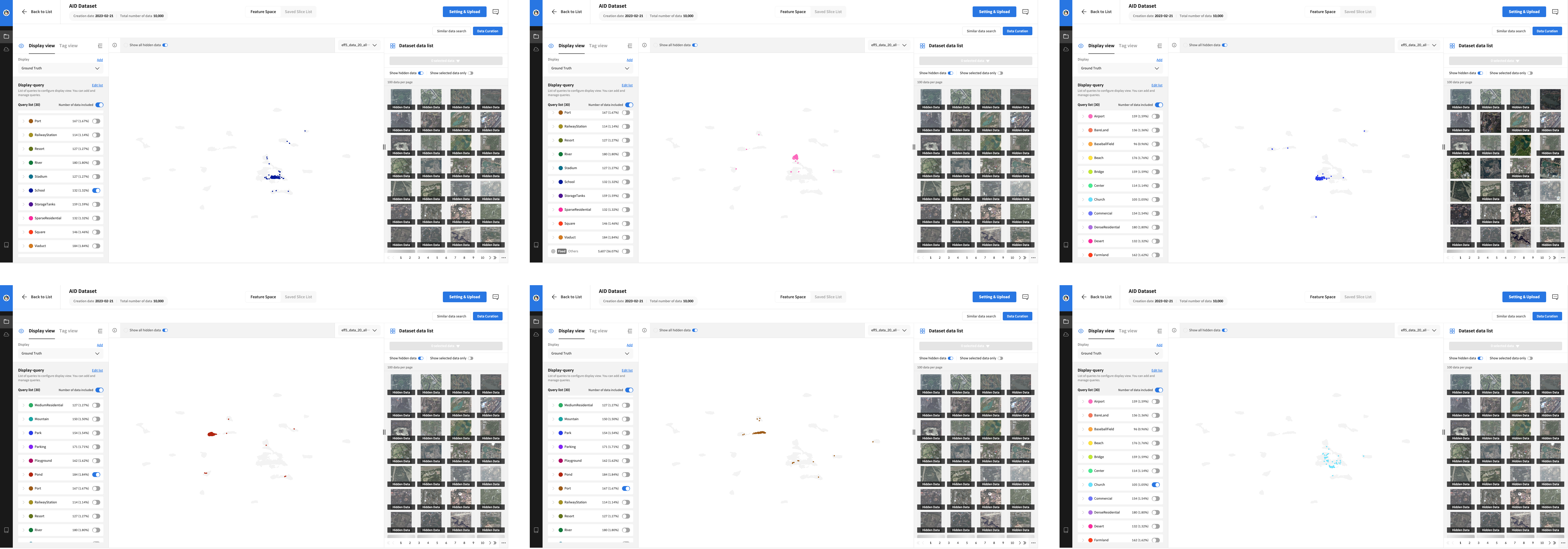 We examined the feature space with the vectors extracted from the model trained on the original 20% data and selected the classes that were deemed to be variably distributed. Then, we inferred the remaining 80% unlabeled data with the previously trained model, curated the inferred data with the selected classes, and selected 10% of the data for additional learning.
We examined the feature space with the vectors extracted from the model trained on the original 20% data and selected the classes that were deemed to be variably distributed. Then, we inferred the remaining 80% unlabeled data with the previously trained model, curated the inferred data with the selected classes, and selected 10% of the data for additional learning.